Data Science Projects
[Capstone Project : Loan Default Prediction]
Project 1 : Unsupervised Learning - PCA & tSNE
Principal Component Analysis - tSNE - Exploratory Data Analysis
In this project, we will explore dimensionality reduction using PCA & tSNE algorithm. We will be using the inbuilt Iris dataset from sklearn package. The data contains information about three types of Iris flower - Setosa, Versicolour & Virginica. For every type of flower there are four features sepal length, sepal width, petal length and petal width.

- EDA to identify any patterns or correlation between features
- Use PCA with 2 components to reduce dimensionality and visualize the data
- Use tSNE with 2 components to reduce dimensionality and visualize the data
Project 2 : Segmentation of Bank customers using clustering techinques
K-Means - DBSCAN - Gaussian Mixture Model
In this project, we will cluster customer data from a bank. The goal is to indentify various customer segments to run marketing campaigns. They have been advised by their marketing research team, that the penetration in the market can be improved. Based on this input, the Marketing team proposes to run personalised campaigns to target new customers as well as upsell to existing customers. Another insight from the market research was that the customers perceive the support services of the bank poorly. Based on this, the Operations team wants to upgrade the service delivery model, to ensure that customers queries are resolved faster.

- EDA to identify and clean data and determine patterns or correlation between features
- Data prepocessing to limit the impact of outliers in the data
- Implement k-means, DBSCAN & GMM models to determine clusters
- Compare the results of the 3 implemented models
- Recomend appropriate campaings for the idenitfied clusters
Project 3 : Prediction of Housing Prices
Linear Regression - Machine Learning - Model Metrics
In this project, we will predict the housing prices of a town or a suburb based on the features of the locality provided to us. In the process, we need to identify the most important features in the dataset. We need to employ techniques of data preprocessing and build a linear regression model that predicts the prices for us.Each record in the dataset describes a Boston suburb or town. The data was drawn from the Boston Standard Metropolitan Statistical Area (SMSA) in 1970.
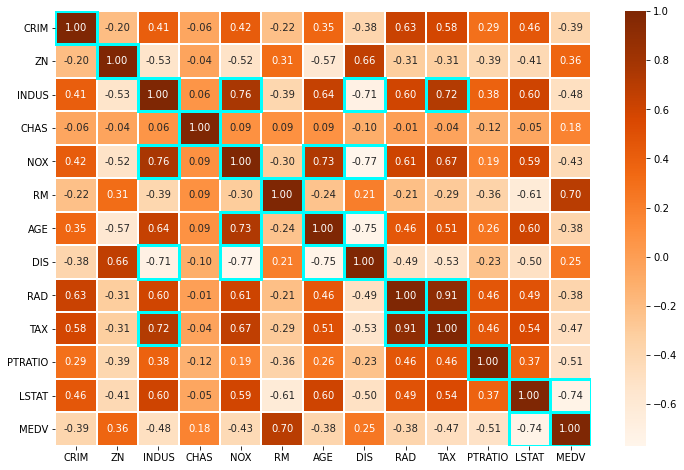
- Statiscal analysis to determine skewness of features
- EDA to determine patterns and correlation between features
- Implementation of linear regression model to predict housing prices
- Feature selection using Variance Inflation Factor
Project 4 : Prediction of Loan Eligiblity
Logistic Regression - k Nearest neighbors - Feature Importance
In this project, we will predict whether a customer is eligible for bank loan. Credit risk is the default in payment of any loan by the borrower. In Banking sector this is an important factor to be considered before approving the loan of an applicant.Dream Housing Finance company deals in all home loans. They have presence across all urban, semi urban and rural areas. Customer first apply for home loan after that company validates the customer eligibility for loan.
Company wants to automate the loan eligibility process (real time) based on customer detail provided while filling online application form. These details are Gender, Marital Status, Education, Number of Dependents, Income, Loan Amount, Credit History and others. To automate this process, they have given a problem to identify the customers segments, those are eligible for loan amount so that they can specifically target these customers.

- Univariate and Bivariate Data Analysis
- Handling of missing data
- Implementation of logistic regression with feature importance
- Implementation of kNN model
- Model comparision and recommendations
Project 5 : Prediction of Loan Eligiblity
Decision Tree - Random Forest Classifier
In this project, we will use the same data set to predict loan eligiblity with tree based models. We will implement Decision trees and Random Forest algorithms for classification.
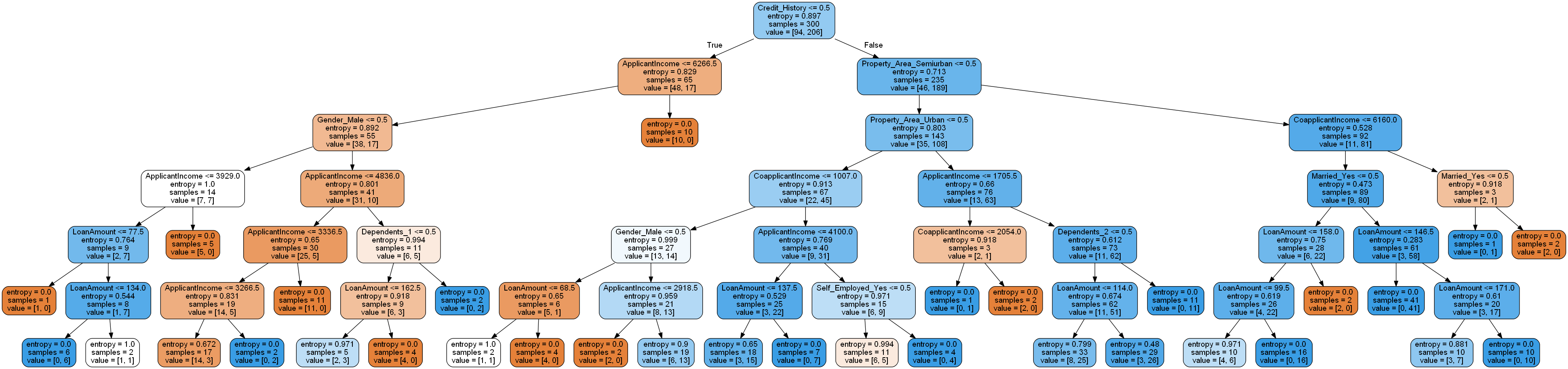
- Implementation of Decision Tree - full depth
- Gneralization of full depth Decision Tree
- Visualizing the tree
- Implementation of Random Forest Model
- Comparing the performance of the both models
Project 6 : Forecasting of Air Passengers
Time Series Forecasting - AR, MA & ARMA ( autoregressive–moving-average )
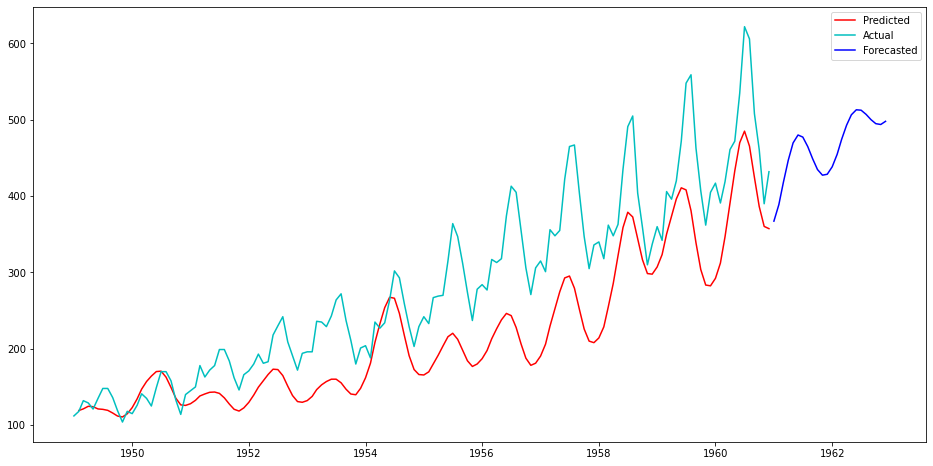
In this project, we will forecast the volume of air passengers based on the historic data. The dataset is from inbuilt dataset in R. The objective is to predict the monthly volume of air passengers for next 24 months.
- Testing stationarity of the data set using ADF (Augmented Dickey-Fuller) test
- Transform the dataset to be stationarity
- Analyzing seasionality, trend and residual features for the dataset
- Implementation of AR, MA & ARMA models to determine the best fit
- Visualizing the actual, predicted and forecasted values